Why you want Databricks Auto Loader
Auto Loader is one of the standout features in Databricks and this post will introduce you to why you’d want to use it to address common data ingestion challenges.
Data ingestion
Fundamentally, data ingestion is the process of taking data from one location to another for further data analysis and transformation. It’s more involved than merely moving data from “A” to “B” and when you factor in requirements such as enforcing data quality, source system data changes and much more, the ingestion process can introduce a lot of complexity.
Any decent data platform will have a fool-proof robust data ingestion process and within Databricks, we have Auto Loader to help tackle data ingestion challenges that will test the robustness of our data ingestion pipelines.
Auto Loader
Auto loader is a Databricks feature that simplifies the process of ingesting data files as they arrive in cloud storage.
Simplifying ingestion
In response to common data ingestion challenges, Auto Loader can tackle these challenges and simplify the data ingestion process as detailed below:
- How can you track which file has been processed?
- Automated “bookkeeping” of processed files
- Automatic discovery of new files to process.
- You don’t need to have special logic to handle late arriving data or keep track of which files have been processed yourself.
- Automated “bookkeeping” of processed files
- Can the ingestion pipeline gracefully handle changes at source?
- Schema inference
- Auto Loader can infer your data schema and detect schema drift on the fly.
- Schema evolution
- It can also evolve the schema to add new columns and restart the stream with the new schema automatically.
- Known schema
- Provide a schema for a dataset.
- Add type hints to enforce a known schema.
- Schema inference
- What about data that doesn’t meet expectations?
- Data rescue
- You can rescue data that doesn’t meet expectations by configuring Auto Loader to rescue data that couldn’t be parsed from your files in a rescued data column.
- The rescued data can be analysed separately while the rest of the data is processed.
- Data rescue
- How do we leverage cloud native resources for ingestion e.g., file notification?
- Auto Loader will set up cloud native resources for file notification e.g., event hub subscriptions.
- Will the solution scale?
- Scalable file discovery allows Auto Loader to ingest billions of files.
- Does the solution require re-engineering for stream or batch use cases?
- Supports configuration of stream and batch modes by default.
- How cost effective is the solution?
- Set up and maintenance is minimised, so the focus remains on making use of the data to be ingested.
- Simplified data ingestion process.
- Reduced overall development effort.
- File notification is much cheaper than directory listing for large numbers of files e.g., millions of files.
One of the key reasons to use Auto Loader is to avoid a complex set up process and the following image taken from the databricks blog shows how Auto Loader can indeed simplify and reduce setup efforts for data ingestion.
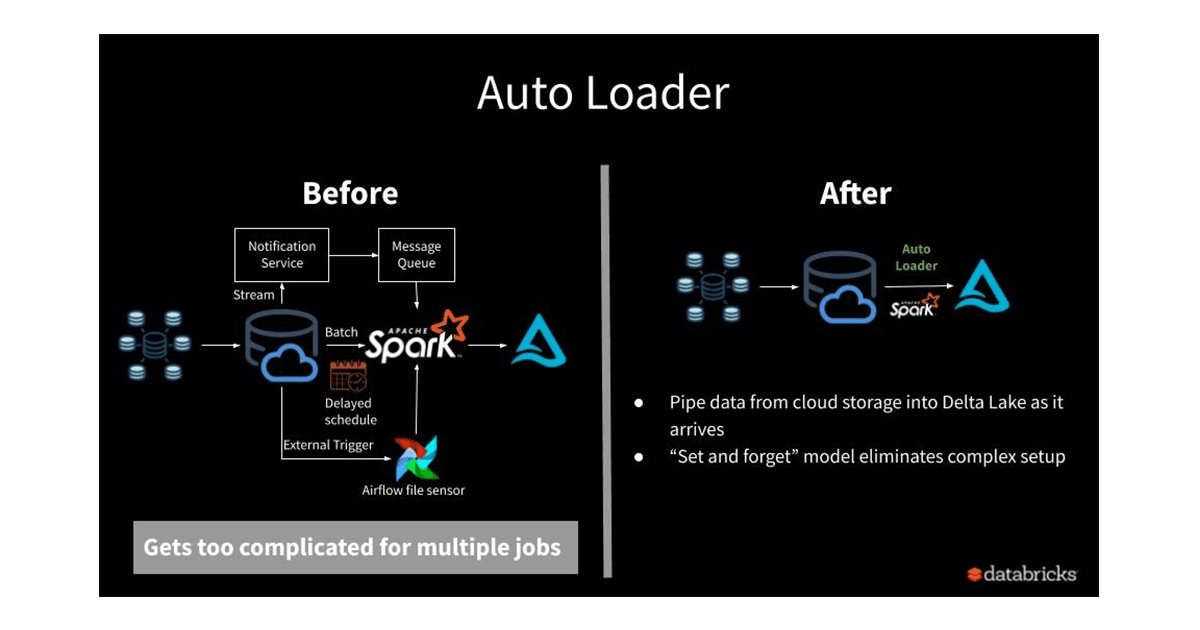
Getting started
Whether or not (and why not?!) you’re convinced about using Auto Loader yet, the next few posts will explore the feature, delve into various use cases, and help address:
- How you keep track of which file has been processed?
- Whether the ingestion pipeline gracefully handles changes at source or data that doesn’t meet expectations?
- How you leverage cloud native resources for ingestion e.g., file notification?
- If the solution will scale?
- How you handle stream or batch use cases?
- How cost effective the solution is?
See you next time.